经典cnn模型们
标签:cnn目录
cnn basic
卷积
自然图像有其固有特性,也就是说,图像的一部分的统计特性与其他部分是一样的。这也意味着我们在这一部分学习的特征也能用在另一部分上,所以对于这个图像上的所有位置,我们都能使用同样的学习特征。
更恰当的解释是,当从一个大尺寸图像中随机选取一小块,比如说 8x8 作为样本,并且从这个小块样本中学习到了一些特征,这时我们可以把从这个 8x8 样本中学习到的特征作为探测器,应用到这个图像的任意地方中去。特别是,我们可以用从 8x8 样本中所学习到的特征跟原本的大尺寸图像作卷积,从而对这个大尺寸图像上的任一位置获得一个不同特征的激活值。
下面给出一个具体的例子:假设你已经从一个 96x96 的图像中学习到了它的一个 8x8 的样本所具有的特征,假设这是由有 100 个隐含单元的自编码完成的。为了得到卷积特征,需要对 96x96 的图像的每个 8x8 的小块图像区域都进行卷积运算。也就是说,抽取 8x8 的小块区域,并且从起始坐标开始依次标记为(1,1),(1,2),…,一直到(89,89),然后对抽取的区域逐个运行训练过的稀疏自编码来得到特征的激活值。在这个例子里,显然可以得到 100 个集合,每个集合含有 89x89 个卷积特征。

假设给定了\(r \times c\)的大尺寸图像,将其定义为\(x_{large}\)。首先通过从大尺寸图像中抽取的\(a \times b\)的小尺寸图像样本\(x_{small}\)训练稀疏自编码,计算\(f = \sigma (W^{(1)}x_{small} + b^{(1)})\)(\(\sigma \)是一个 sigmoid 型函数)得到了k个特征, 其中\(W^{(1)}\) 和\(b^{(1)}\)是可视层单元和隐含单元之间的权重和偏差值。对于每一个\(a \times b\)大小的小图像\(x_s\),计算出对应的值\(f_s = \sigma (W^{(1)}x_s + b^{(1)})\),对这些\(f_{convolved}\)值做卷积,就可以得到\(k \times (r - a + 1) \times (c - b + 1)\)个卷积后的特征的矩阵。
**【即一个3x3的卷积核,和图中3x3的小块对应元素相乘,然后再相加,得到一个值[其实就是element-wise乘积,再对所有元素求和。。]。得到的新矩阵就是(5-3+1)x(5-3+1)=3x3。
而如果有m个3x3的卷积核,那就得到了m个3x3的结果,当然,卷积核的大小可以不一样。
如果有4个通道,2个卷积核,那么最终得到两个图(2个通道),每个图是4个通道对应的卷积结果对应元素相加,再经过激活得到的】**
权值共享:
有m个axb的卷积核,那么就只有mxaxb个参数,因为生成最终m个feature map的过程中,生成每个feature map时都是共享同一个axb的卷积核(axb个参数)。
池化
在通过卷积获得了特征 (features) 之后,下一步我们希望利用这些特征去做分类。理论上讲,人们可以用所有提取得到的特征去训练分类器,例如 softmax 分类器,但这样做面临计算量的挑战。例如:对于一个 96X96 像素的图像,假设我们已经学习得到了400个定义在8X8输入上的特征,每一个特征和图像卷积都会得到一个 (96 − 8 + 1) * (96 − 8 + 1) = 7921 维的卷积特征,由于有 400 个特征,所以每个样例 (example) 都会得到一个 892 * 400 = 3,168,400 维的卷积特征向量。学习一个拥有超过 3 百万特征输入的分类器十分不便,并且容易出现过拟合 (over-fitting)。
为了解决这个问题,首先回忆一下,我们之所以决定使用卷积后的特征是因为图像具有一种“静态性”的属性,这也就意味着在一个图像区域有用的特征极有可能在另一个区域同样适用。因此,为了描述大的图像,一个很自然的想法就是对不同位置的特征进行聚合统计,例如,人们可以计算图像一个区域上的某个特定特征的平均值 (或最大值)。这些概要统计特征不仅具有低得多的维度 (相比使用所有提取得到的特征),同时还会改善结果(不容易过拟合)。这种聚合的操作就叫做池化 (pooling),有时也称为平均池化或者最大池化 (取决于计算池化的方法)。
下图显示池化如何应用于一个图像的四块不重合区域。
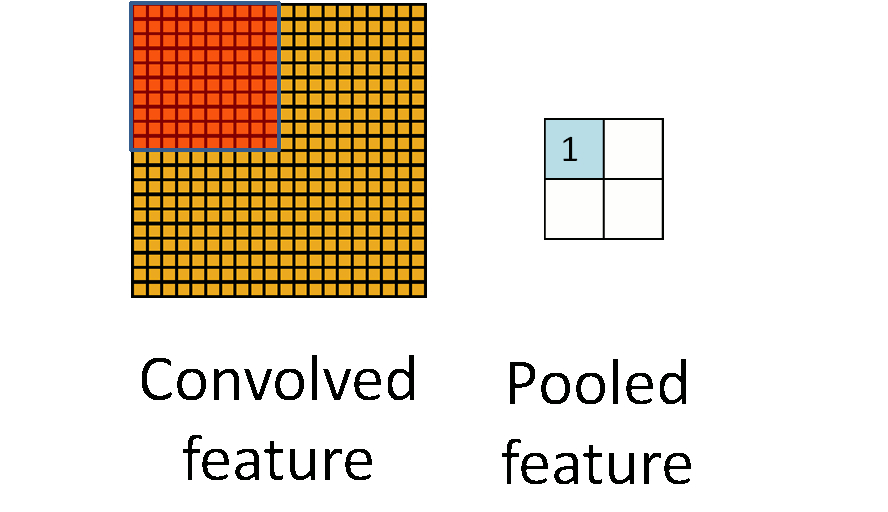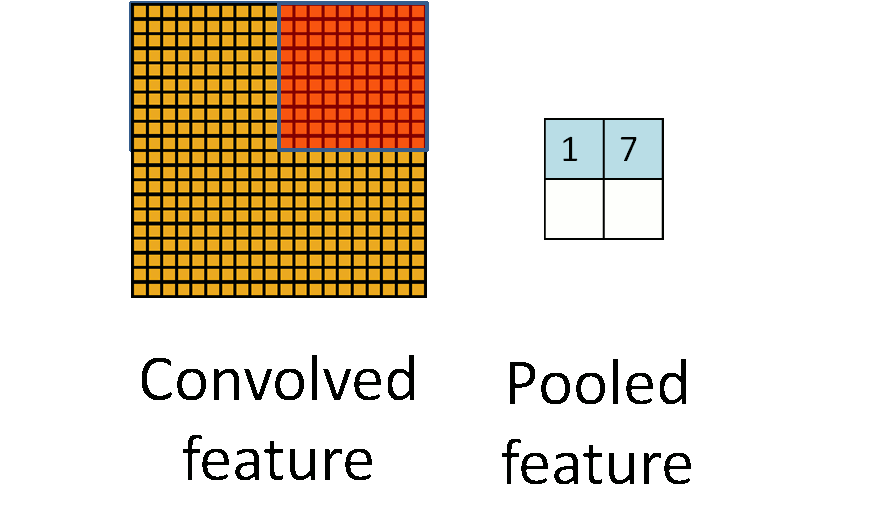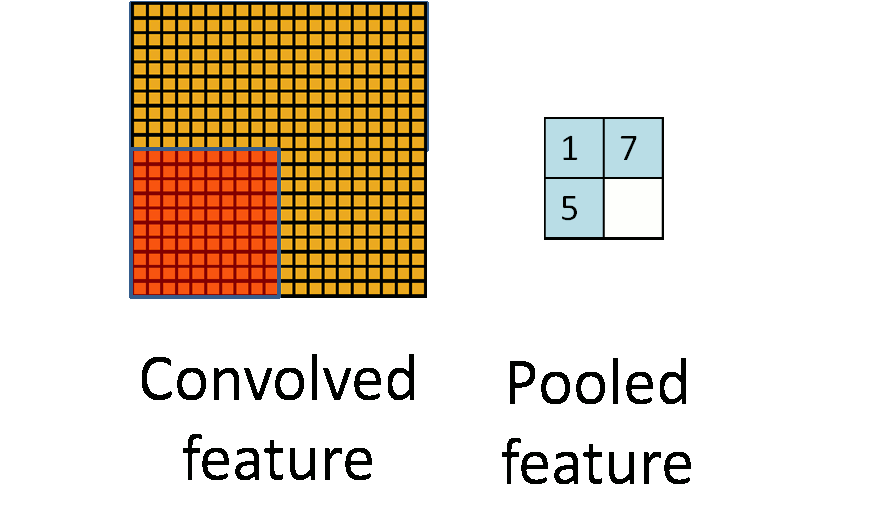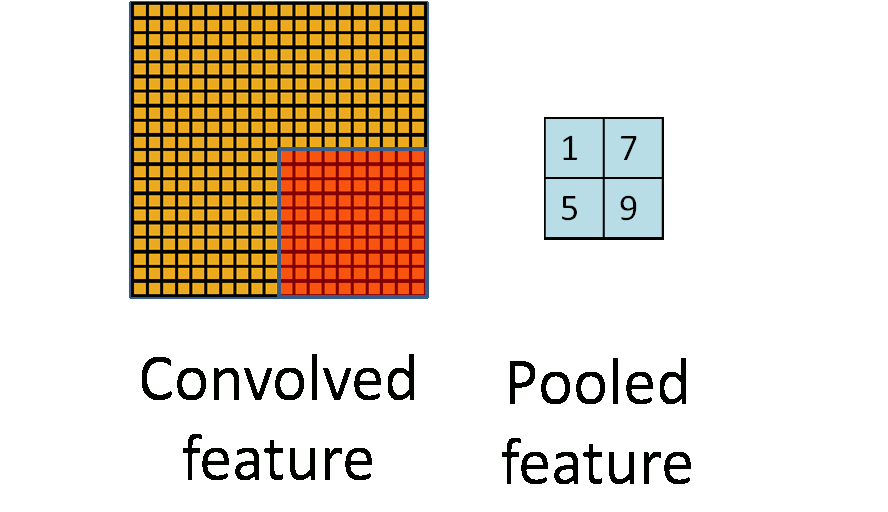
如果人们选择图像中的连续范围作为池化区域,并且只是池化相同(重复)的隐藏单元产生的特征,那么,这些池化单元就具有平移不变性 (translation invariant)。这就意味着即使图像经历了一个小的平移之后,依然会产生相同的 (池化的) 特征。在很多任务中 (例如物体检测、声音识别),我们都更希望得到具有平移不变性的特征,因为即使图像经过了平移,样例(图像)的标记仍然保持不变。例如,如果你处理一个MNIST数据集的数字,把它向左侧或右侧平移,那么不论最终的位置在哪里,你都会期望你的分类器仍然能够精确地将其分类为相同的数字。
形式上,在获取到我们前面讨论过的卷积特征后,我们要确定池化区域的大小(假定为\(m \times n\)),来池化我们的卷积特征。那么,我们把卷积特征划分到数个大小为\(m \times n\)的不相交区域上,然后用这些区域的平均(或最大)特征来获取池化后的卷积特征。这些池化后的特征便可以用来做分类。
发展历程
包括lenet, alexnet, vgg, googlenet, resnet等。
inception发展过程: http://blog.csdn.net/u010402786/article/details/52433324
科普贴:
https://zhuanlan.zhihu.com/p/27642620?utm_source=itdadao&utm_medium=referral
原创文章,转载请注明出处!
本文链接:http://hxhlwf.github.io/posts/image-classical-cnns.html